Finding Copernicus - Exploring RAG limitations in context-rich documents
In Back to the Future, what was Doc Brown's dog's name in 1955? A seemingly simple movie trivia question exposes fundamental limitations in current AI systems. Answering this proves surprisingly challenging for our current technology.

Now that I have a first RAG implementation in OpenGPA, I've started building a project around a 'movie chat' idea where a user could ask trivia questions and a RAG based agent could look up for answers.
- In Back to the Future, what is Doc Brown’s dog name in 1955?
- In Star Wars Episode IV, how many planets does Luke visit?
It just didn't work. Even simple trivia questions can't be answered by RAG no matter how I've tried to approach the problem. This is due to the complex context-dependent and time-dependent nature of movie scripts.
In this post I explore what is going on, the state of RAG, and current limitations. I introduce the idea of a RAG benchmark based on movie scripts and explore ideas to solve this context issue in RAG.
Introduction to RAG
Retrieval Augmented Generation (RAG) is a technique to provide AI Agents with access to knowledge from external sources such as documents. It is used to access data as varied as company documentation, user manuals, history of support tickets, slack conversations., etc.
A simple implementation of RAG relies on the concept of embeddings and vector search. The idea is quite simple:
- The document is split into separate chunks of content
- Each chunk is encoded into embeddings (numerical vector space in which language models are working)
- Embeddings are stored in a vector database
- The database can be searched for relevant chunks given a query
The main difference with regular keyword search comes from the use of the embeddings which allow for 'similarity' search (which relies on a mathematical measure between vectors in the embedding space).
Take this quote for example:
“Walking is the most perfect form of motion for a person who wants to discover the true life.” - Thoreau
A search for 'hiking' using keywords wouldn't pick up this chunk. However, in embedding vector space, it would be returned given the proximity of walking and hiking concepts in the embedding vector space.
The current version of OpenGPA implements such a vector-based RAG, it works well for a large variety of documents, especially descriptive documents containing independent facts or definitions.
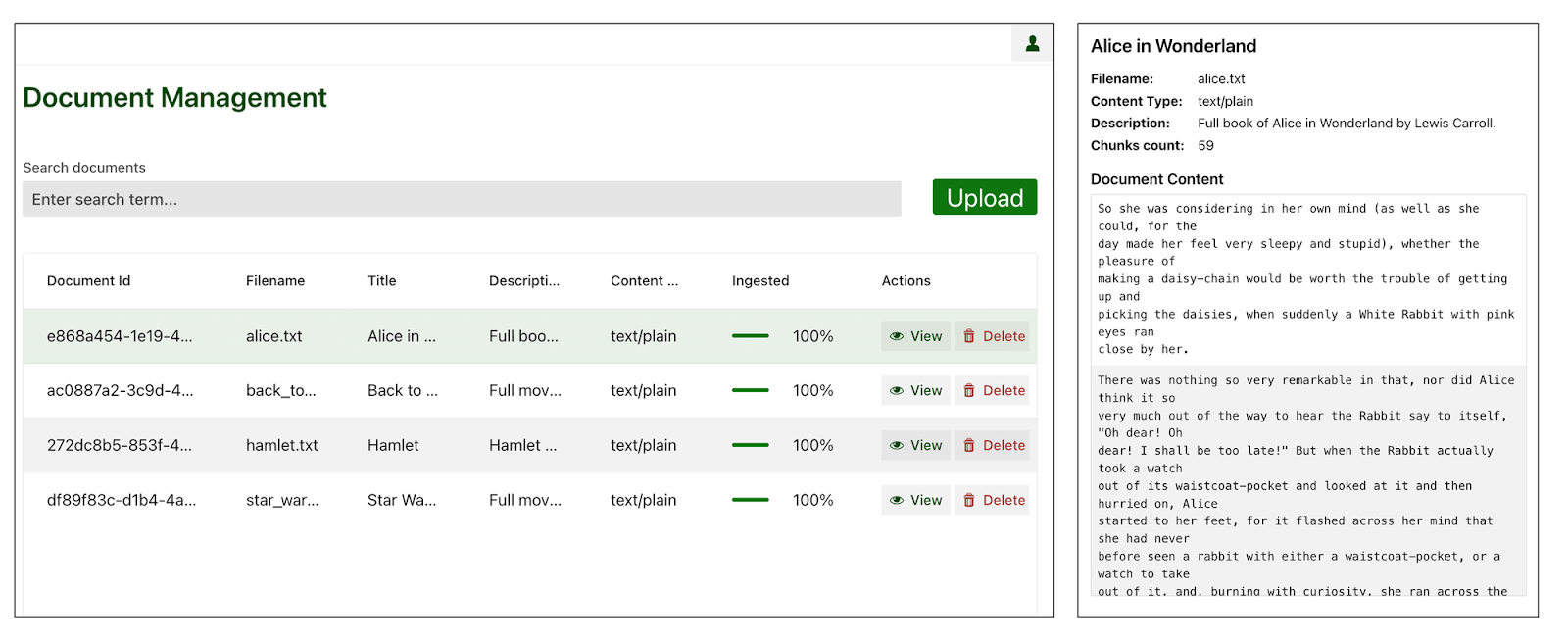
The movie script problem
The issue with movies, but also with chat conversations or any other form of temporal document, is that a lot of the context of what you are reading depends on what has happened in the previous sections both in temporality and in scene/character interactions.
A single chunk from a movie depends heavily on the overall context in which it happens, in terms of time and location, but also of the interdependence between characters and scenes.
When looking at a car owner manual, you can open the tire section and get the recommended tire pressure by just reading the required section. You don't need to remember anything about the engine oil section. Well, in a movie script, you actually do need to remember a lot of context and details in order to figure out what is going on at any point in time.
Lack of context
In Back to the Future, what is Doc Brown’s dog name in 1955?
In this case, the RAG will return dozens of chunks related to dogs but these chunks are part of the 1985 storyline where the dog is named Einstein and travels in the time machine. In all experiments, the RAG approach leads to a naive answer of 'einstein' instead of 'copernicus'.
The core issue is that the chunks lack the overall story context and the context needed to answer a question is very much question and document-dependent. One could imagine enriching each chunk with an estimated location or year. But what if the question requires the context of the time of day, season, indoor or outdoor, etc...
It is easy to come up with the required context when you know the question but it is much harder to have a generic solution a-priori.
Lack of indirect relationship
In Star Wars Episode IV, how many planets does Luke visit?
In the case of this Star Wars question, the issue is that to answer the question you need to understand that Luke is onboard a spaceship named Millenium Falcon and that you should look for places where it lands. Naively looking for chunks mentioning planets will return too much data while looking for chunks related to Luke and planets will return too little.
Another complexity of this question is that it requires an identification of all occurrences. It is not sufficient to find the right chunk containing the answer being looked for, it requires to find all chunks related to the question and with enough context so to filter the planets visited by Luke (indirectly by the ship) or merely mentioned as part of the plot.
Exploring the Graph RAG solution
An attempt to solve some of these limitations was proposed by Microsoft Research under the term Graph RAG. The core idea is to use a LLM to process each chunk and extract interesting entities and relationships into a graph that summarizes the document content.
When doing a search, the system will leverage both the graph (and the context summary associated with it) as well as the vector database, in an attempt to return more relevant chunks.
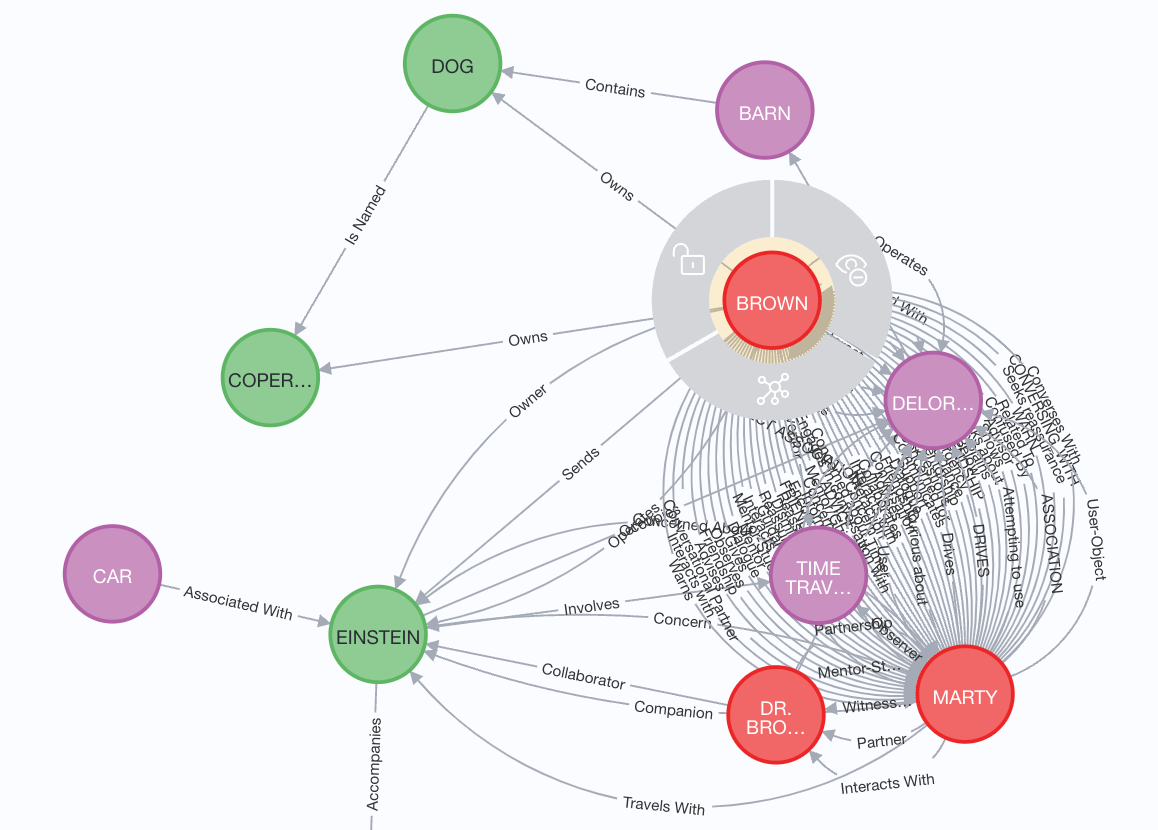
The open-source R2R project has an implementation of this approach running on top of a Neo4J graph database. It made it an awesome tool to experiment and see if Graph would solve the Copernicus challenge.
As we can see in the graph below, it does capture really well all the key entities and relationships from the movie. We can easily see that BROWN owns a DOG named EINSTEIN and another one named COPERNICUS. Unfortunately, we are still lacking some key context to figure out which one should be the one in 1955.
The need for better contextualisation
The limitations of both standard RAG and Graph RAG suggest a need for a more holistic approach to context retrieval. The chunks can't be treated in isolation and need to be part of a bigger structure that provides key contextual elements. Although Graph RAG moves in this direction, it is insufficient to solve problems like the one discussed here.
In a sense, this is similar to human reading. When reading this paragraph, you don't remember the exact words of the previous ones. You remember however the broad context, the questions being asked, and some of the high-level solutions discussed. A contextualized RAG approach would need to proceed the same way, informing the context of a given chunk by its relationship to the whole document.
Note that this is not about having a temporal model of the document, although this would help in our case, it wouldn't be sufficient. We could imagine a benchmark using:
- travel guides: where the model should be geographical (understanding which chunk relates to which region or step in a journey)
- legal documents: where the model should be version based as a piece of law or judgement relates to one version of the law at one point in time
- science documents: where the model would be specific to the space in which the science is happening
Next steps
I believe this "movie trivia" idea is an excellent "hard" topic for RAG and it would be worthwhile exploring the creation of a benchmark made out of movie scripts and trivia questions encompassing the temporal, geographical, and relationship context.
In addition, exploring novel approaches to RAG and chunk contextualization, leveraging LLM unique capabilities to not only extract entities but also provide context summarization might be something to explore further to eventually find Copernicus.
I'll surely keep researching this topic, so subscribe to this blog to stay in touch and please comment if this raises questions or ideas on a path forward. I'm also curious of other projects/techniques which might be able to solve this copernicus challenger.